

From the very beginning, I have been frustrated about messaging of these jab with regards to manufacturing these jabs to a pharmaceutical grade quality. Part of this quality issue are the analytical methods. Often hidden behind either proprietary shields, or more often in chemistry and pharmaceutical journals that no one reads, there is a wealth of information about ongoing issues with respect to the quality measurements of the jab. And the problems with knowing what they do in the body.
Critical Quality Attributes (CQA)
What is a CQA? CQAs are the physical, chemical, or biological characteristics that ensure the desired product quality, when falling within appropriate limits, ranges or distributions. So who determines WHAT CQAs will be used? What the parameters of quality are? Well, the manufacturers of course. They are the ones making the product. Surely they know what and how to make something to a high quality standard, right?
Usually CQAs are derived from the totality of the manufacturer’s experience during the design process, in developing this product and other mRNA therapeutics, published criteria, and with the results obtained from Process 1 lots. This of course, takes time and knowledge leveraged from other products. Only there was little time, and little prior knowledge (only maybe a bit for the LNPs from Onpattro). So we are STILL developing the CQAs. To me, this is mind boggling.
Each CQA is required to conform to the following
1. a specification defined as a list of tests,
2 a reference to an analytical procedure and,
3. an acceptance criterion to which the drug substance should meet and be considered acceptable for its intended use.
Does everyone see the problem here? You have to define WHAT is a quality measure for these jabs, the right test to measure that, and then what is acceptable for quality or safety (i.e. should it be 99.9% pure or is 98% pure good enough?)
There are 3 parts of this jab that need CQAs
I think most people know the 2 major parts of these jabs.
the mRNA construct (known as the drug substance)
the LNPs in a dispersion format in the sucrose/buffer in the vials (the drug product)
Usually included in determining the mRNA construct, there is a third part
3. the expressed spike protein from the translation of the mRNA in the body (the ribosomes)
That part? The actual active part that is required to make the antibodies? The pro-drug concept? Well that requires another whole substack as is STILL THE outstanding issue, imho. However, for now, let us just look at the quality measurements of the mRNA
The mRNA construct
Ok, if you were in charge of ensuring the quality of the mRNA, what would you measure?
how much, or content
how pure it is
is it intact? ie fragmented and truncated modRNA
all the left over stuff from making the modRNA ie dsRNA and the DNA template
OOOPs, there is one more thing. Has the mRNA construct been transcribed from the DNA appropriately and without errors?
The Analytical Methods Used for the modRNA construct
For Process 1 jabs, Pfizer sequenced the DNA template but for process 2 jabs, they used qPCR to measure a specific part of the mRNA as part of the regular ongoing quality measurement of the modRNA.
For the FIRST batch they made using the Process 2, Pfizer sequenced the mRNA construct in order to show that the right mRNA is being transcribed.

That’s good enough, right? One batch only?
For ongoing process 2 jabs, they used RT-PCR, which doesnt measure the entire modRNA construct as I understand it. So is this a good enough analytical method for this CQA? What do you think?
USP Compendial Standards
So these issues of CQAs and standards are known and need to be fixed. That is why we have compendium, the helps inform on what the CQAs should be and what analytical methods are best and HOW to do the method. It does not decide what is the acceptable limit; that is the perview of the regulatory agencies.
OK. What does the USP recommend in order to test that the mRNA is the actual mRNA construct you want?
high throughput sequencing
Sanger sequencing
RT-PCR
so yup, sequencing each lot of mRNA will be the defacto standard. RT-PCR is maintained as third line (my guess is for the time being)
Why is this important?
modRNA variants
The virus replicates and makes their own spike proteins. Thus the RNA in the virus is replicated to grow more viruses, since it is an RNA virus. (no DNA in SARS-CoV2). What is the error rate and does that explain the virus variants?
The process is well explained in this pre-print article which compares the error rate between the virus and the mRNA vaccines for the spike protein.
RNA polymerase inaccuracy underlies SARS-CoV-2 variants and vaccine heterogeneity
Both the SARS-CoV-2 virus and its mRNA vaccines depend on RNA polymerases (RNAP); however, these enzymes are inherently error-prone and can introduce variants into the RNA.
For the virus, these researchers found viral RNA-dependent RNAP (RdRp) makes ~1 error every 10,000 nucleotides – which was higher than previous estimates
Vaccine mRNA is the product of in vitro transcription (IVT) by T7 phage polymerase from a codon-optimized, Spike-encoding DNA construct. T7 polymerase also commits errors during transcription at frequencies ranging from 10−4 to 10−6
This was a known fact prior to the launch of the vaccines.
So these researchers compared the errors between the virus and the DNA template using T7 polymerase for transcription into mRNA for the vaccines. What do we see?
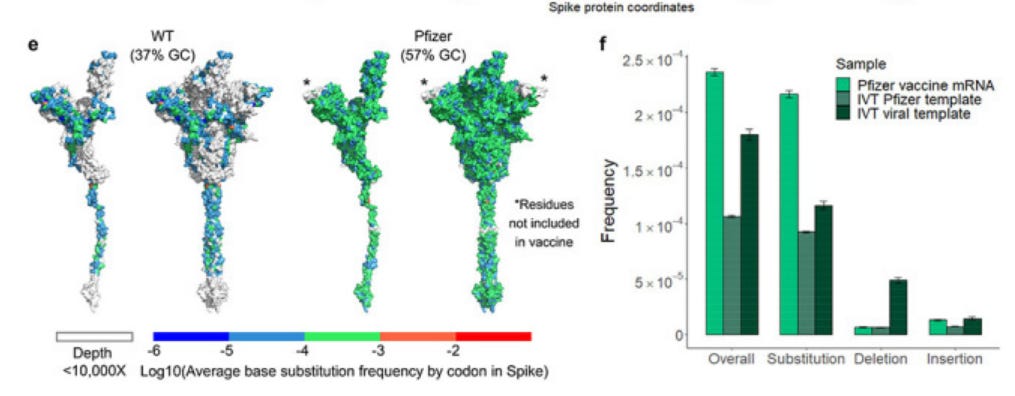

Here is what they conclude
At a frequency of 1 in 5,000 nucleotides, the pace of vaccine variants appears balanced against viral evolution and suggests that the majority of mRNA produced encodes variant Spike proteins. The role of vaccine heterogenicity in the immune response is currently unknown.
Of course they think this is a GOOD THING, because you know, antibodies, schmantibodies.
Vaccine variants could promote a more diverse immune repertoire, which offers benefits in the context of a rapidly evolving virus. However, other uses like cancer vaccines or mRNA drugs may require high fidelity transcription to reduce the risk of autoimmunity or improve clinical efficacy.
But that is NOT WHAT WE WANT IN A VACCINE OR AN MRNA DRUG. We need the mRNA to be the same or as close to the same each time because variablity in response and efficacy should come from the patient, not the drug product. Keep in mind that the mRNA construct is 4250 nucleotides. That means EACH modRNA likely has 1-2 errors in it BEFORE it gets to the ribosomes to be translated into protein. Welcome to pro-drugs. And how many mRNA strands are there in each 30ug dose? About 10 trillion is an estimate.
How do you know what the adverse effects of these mRNA variants are? Can the mRNA code for a more “toxic” spike?
So as a regulator what do you do? Insist that each mRNA strand is the same as the next? How much error do you allow? What are the risks of these ‘variants?”
And most interesting of all, this preprint was finally published in April 2024. Keep in mind this was funded by the NIH.
And the final “peer” reviewed article does NOT MENTION VACCINE MRNA VARIANTS on the abstract (which is not true with the preprint). However, it is behind a paywall. Of course. And it took 2 years for an NIH funded paper to get to print. Hmmmmmm. Anyone have access and can tell me if they report the error rates of transcription using the T7 polymerase for the IVT process of the vaccine?
I hope to show everyone the other measurement problems with the vaccine. Next substack will be measuring modRNA content and intactness which is fairly straighforward. Then, purity which is STILL A HUGE UNMITIGATED MESS.
In summary
the production of the modRNA from the DNA template has error rates higher than that seen with the virus
this results in at least 1 error per modRNA construct
with approximately 10 trillion mRNAs in each dose, that is a lot of errors (keep in mind only 1-2% of that mRNA gets translated into protein, but that is still um billions)
measurement of that error requires sequencing and other techniques. Pfizer did not do that for Process 2 jabs (and I am not sure they did it for Process 1 jabs). They used RT-PCR. Moderna uses Sanger Sequencing for their modRNA identification, BTW
The United States Pharmacopoeia is asking for sequencing in their draft guidelines. When they finally get passed, Pfizer will likely have to comply. Which begs the question, are they doing it now? If not, why not?
How many errors are “acceptable” for a regulatory standard?
Can this every be improved to match the virus or improve upon such that we get a “pharmaceutical grade” product?
And because this is a ‘pro-vaccine’ the final product, i.e. the spike protein, still has to be translated by the ribosomes with their OWN error rate.
Thanks for reading and please comment with anything I may have gotten wrong.
Oh and pray the rosary
Explain to me how turning our cells into viral antigens confers immunity father than disease?
“Those who make us believe in absurdities, can make us commit atrocities.” Voltair
Clear and important, as always! As you say, tragically, much of this was already known and should not be a surprise. Now, that we have the numbers, it should be even more convincing!!! In my book, I raised the question about T7 pol creating lots of fragmented species, which, I argued, based on the mechanisms of this polymerase, would create also dsRNAs. Did the paper that you mentioned consider these as well? I have to read through the preprint - even though, as you point out, the "peer" review likely has whitewashed a lot of things. Thanks again!